Las animaciones Flash son cada vez más frecuentes en Internet. Y a medida que pasa el tiempo nos encontramos con más aplicaciones de una cierta envergadura realizadas en este formato.
La herramienta utilizada típicamente para crear aplicaciones en formato Flash es el propio Macromedia Flash, un producto comercial (precio cercano a los 810€ para la versión Pro 8) sobre el que se puede encontrar información en
http://www.adobe.com/es/products/flash/flashpro/
Pero, como suele ocurrir, hay alternativas.
Por ejemplo, para crear pequeñas animaciones existen muchas utilidades shareware e incluso alguna gratuita. Una de las gratis es la ya abandonada Powerbullet, que todavía se puede descargar de la página de CdLibre. Una de las shareware más interesantes es SWiSH Max (US$99.95), que permite crear multitud de efectos con rapidez.
Y si queremos crear "aplicaciones" con ventanas, menús, etc., también tenemos una opción gratuita. Se trata de OpenLaszlo. Es una aplicación de código abierto (open source) que permite crear programas usando XML y JavaScript, y posteriormente los compila para obtener un ejecutable en formato Flash (.SWF), que podríamos incluir en cualquier página Web. Además, es multiplataforma: existen versiones para Windows, Linux y MacOS-X.
Es un proyecto de un tamaño respetable: la descarga de la versión 3.3.3 es de 48-55 Mb (según el sistema operativo), y la instalación incluye el servidor web Tomcat, por lo que puede ocupar algo más de 150 Mb (que , según el tamaño de cluster, puede suponer unos 500 Mb de ocupación real, por la gran cantidad de ficheros pequeños incluidos).
Para quien le apetezca echarle un vistazo, existe una presentación en línea (Laszlo in 10 minutes) que muestra los conceptos básicos, a partir de pequeños fuentes que podemos modificar y recompilar en la propia web.
28 diciembre 2006
20 diciembre 2006
El formato "Big Endian" y el "Little Endian"
Estas palabras se usan para referirse a las dos formas en que se pueden guardar los números que ocupan más de un byte.
Vamos a verlo usando como ejemplo el número 5. Si lo expresamos en binario con 4 bits, su equivalencia es 0101. Si lo hacemos con 8 bits, sería 00000101. Pero si usamos más de un byte para representarlo, por ejemplo porque se tratara de un número "entero corto", usando la nomenclatura del lenguaje C, tenemos que el número 5 equivaldría a 16 dígitos binarios: 00000000 00000101.
Por tanto, ahora este número 5 queda representado como 2 bytes. El de la izquierda es el byte más significativo (MSB) y el de la derecha es el bit menos significativo (LSB). Estos nombres vienen de que un cambio en el byte de la derecha hace que el número cambie poco (por ejemplo, 00000000 00000100 = 4 en decimal), mientras que un cambio en el byte de la izquierda provoca cambios mucho más grandes (00000001 00000101 = 261 en decimal).
Pues bien, según la arquitectura del ordenador puede ocurrir que esos dos bytes se guarden en el orden que hemos visto: 00000000 00000101 (primero el MSB y luego el LSB) o al contrario (00000101 00000000). Lo primero, que a priori es lo que podría parecer más natural, es lo que se hace en procesadores como los de la familia PowerPc (usados en muchos ordenadores Apple, por ejemplo). Lo segundo, aunque parezca más enrevesado, es lo que se hace en la mayoría de procesadores de Intel, como los usados en los ordenadores PC.
El primer formato (MSB LSB) es lo que se conoce como Big Endian, porque eso de que el extremo más grande aparece en primer lugar. El segundo formato (LSB MSB) es lo que se conoce como Little Endian, porque se almacena primero el dato más pequeño.
¿Y eso en qué afecta a un programador? En que muchas veces deberemos saber con qué plataforma se ha creado un fichero de datos, para poderlo interpretar correctamente.
Por ejemplo, si leemos un fichero que contiene un dato "entero corto", de 2 bytes, formado por la secuencia 00000101 00000000, y ese fichero se ha creado con un ordenador basado en un Pentium u otro procesador de Intel (Little Endian), podemos suponer que ese número es un 5. Por el contrario, si el dato se ha creado desde un equipo Apple clásico, la secuencia 00000101 00000000 estaría en formato Big Endian, luego equivaldría al número 1280.
En general, en caso de que un fichero contenga datos numéricos de más de un byte, deberíamos saber si están almacenados en formato Little Endian o Big Endian, e intercambiar el orden de los bytes después de leer, si fuera necesario.
Como primera curiosidad, existen arquitecturas que permiten escoger la "endianness" que se prefiere usar (como IA64, MIPS y ARM) y que reciben el nombre de "bi-endian". En estos sistemas, normalmente este cambio se puede hacer por software (al arrancar el equipo,por ejemplo), pero en algún caso se ha de realizar por hardware (como podría ser cambiando un jumper en la placa base).
Como segunda curiosidad, el nombre de "Big Endian" y de "Little Endian" se tomó irónicamente de "Los viajes de Gulliver", en que aparece una discusión sobre si un huevo hervido debería empezar a comerse abriéndolo por su extremo pequeño o por su extremo grande.
Vamos a verlo usando como ejemplo el número 5. Si lo expresamos en binario con 4 bits, su equivalencia es 0101. Si lo hacemos con 8 bits, sería 00000101. Pero si usamos más de un byte para representarlo, por ejemplo porque se tratara de un número "entero corto", usando la nomenclatura del lenguaje C, tenemos que el número 5 equivaldría a 16 dígitos binarios: 00000000 00000101.
Por tanto, ahora este número 5 queda representado como 2 bytes. El de la izquierda es el byte más significativo (MSB) y el de la derecha es el bit menos significativo (LSB). Estos nombres vienen de que un cambio en el byte de la derecha hace que el número cambie poco (por ejemplo, 00000000 00000100 = 4 en decimal), mientras que un cambio en el byte de la izquierda provoca cambios mucho más grandes (00000001 00000101 = 261 en decimal).
Pues bien, según la arquitectura del ordenador puede ocurrir que esos dos bytes se guarden en el orden que hemos visto: 00000000 00000101 (primero el MSB y luego el LSB) o al contrario (00000101 00000000). Lo primero, que a priori es lo que podría parecer más natural, es lo que se hace en procesadores como los de la familia PowerPc (usados en muchos ordenadores Apple, por ejemplo). Lo segundo, aunque parezca más enrevesado, es lo que se hace en la mayoría de procesadores de Intel, como los usados en los ordenadores PC.
El primer formato (MSB LSB) es lo que se conoce como Big Endian, porque eso de que el extremo más grande aparece en primer lugar. El segundo formato (LSB MSB) es lo que se conoce como Little Endian, porque se almacena primero el dato más pequeño.
¿Y eso en qué afecta a un programador? En que muchas veces deberemos saber con qué plataforma se ha creado un fichero de datos, para poderlo interpretar correctamente.
Por ejemplo, si leemos un fichero que contiene un dato "entero corto", de 2 bytes, formado por la secuencia 00000101 00000000, y ese fichero se ha creado con un ordenador basado en un Pentium u otro procesador de Intel (Little Endian), podemos suponer que ese número es un 5. Por el contrario, si el dato se ha creado desde un equipo Apple clásico, la secuencia 00000101 00000000 estaría en formato Big Endian, luego equivaldría al número 1280.
En general, en caso de que un fichero contenga datos numéricos de más de un byte, deberíamos saber si están almacenados en formato Little Endian o Big Endian, e intercambiar el orden de los bytes después de leer, si fuera necesario.
Como primera curiosidad, existen arquitecturas que permiten escoger la "endianness" que se prefiere usar (como IA64, MIPS y ARM) y que reciben el nombre de "bi-endian". En estos sistemas, normalmente este cambio se puede hacer por software (al arrancar el equipo,por ejemplo), pero en algún caso se ha de realizar por hardware (como podría ser cambiando un jumper en la placa base).
Como segunda curiosidad, el nombre de "Big Endian" y de "Little Endian" se tomó irónicamente de "Los viajes de Gulliver", en que aparece una discusión sobre si un huevo hervido debería empezar a comerse abriéndolo por su extremo pequeño o por su extremo grande.
06 diciembre 2006
Anjuta ha muerto! Viva Geany!
No, siendo estrictos eso no es totalmente cierto. Anjuta no ha muerto, pero ha evolucionado.
Anjuta es un IDE (entorno de desarrollo integrado) para Linux, que permitía crear con rapidez pequeños programas, compilarlos y comprobar su funcionamiento. El editor de las versiones 1.x tenía refinamientos como realzar la sintaxis en colores, emparejar llaves y paréntesis, permitir completar el código...
Para mí era el rey para los pequeños programas, mucho más cómodo de utilizar que entornos más pesados, más orientados a proyectos de gran tamaño, como KDevelop. Pero el tiempo ha pasado, y Anjuta ha evolucionado. En las versiones 2.x es "casi imprescindible" crear un proyecto para cualquier cosa. Y si abrimos un único fuente (como el clásico "Hola Mundo"), podremos editarlo, pero no aparecerá en el menú la opción de Compilar. Además, el número de dependencias de otros paquetes ha aumentado, lo que hace que a más de una persona le haya costado incluso ponerlo en funcionamiento...
Por eso, para mí, ha llegado el momento de decir "El rey ha muerto! Viva el (nuevo) rey!", porque existe alternativa. Otro IDE de pequeño tamaño podría ocupar el (maravilloso) lugar de Anjuta 1.2. Se trata de Geany, con características muy similares, aunque todavía se encuentra en fase beta.
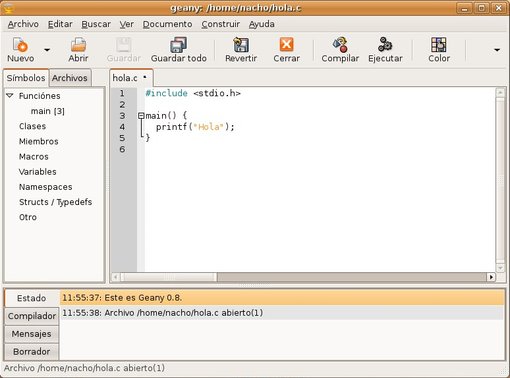
¿Geany es la solución para editar y compilar fuentes individuales desde Linux? Todavía no completamente. Aún tiene algún fallo y alguna carencia de relativa importancia. Por ejemplo, en la versión 0.8, la traducción al castellano tiene más de una errata (aun así, será más cómoda que trabajar en inglés para quien no maneje este idioma con soltura); cuando ejecutamos una aplicación en algunas distribuciones de Linux (pocas, afortunadamente *), la ventana de terminal se cierra inmediatamente, sin dar tiempo a leer lo que ha aparecido, y eso no es práctico para probar programas no interactivos; además, en mi caso, tras pulsar el botón "Guardar todo" la aplicación se ha cerrado misteriosamente, y luego no quería volver a arrancar, hasta que no he borrado su carpeta de configuración (".geany")... decididamente hay cosas por corregir.
Pero todavía es un programa en fase inicial. De hecho, insisto en que yo he probado la versión 0.8 y ya está disponible para descarga la 0.9. Quizá incluso esas "pequeñeces" ya estén corregidas. Y si no, la versión 0.10 se espera para Navidad de este año 2006.
Esperemos que este proyecto nos haga la vida más cómoda a los que con frecuencia trabajamos con pequeños fuentes bajo Linux. De momento, las expectativas no son malas...
¿Más detalles? http://geany.uvena.de
(*) Yo he tenido este problema con Ubuntu 6.10, pero no en Fedora Core 5. En un comentario posterior a este artículo tienes más detalles sobre cómo solucionarlo si te encuentras este problema.
Anjuta es un IDE (entorno de desarrollo integrado) para Linux, que permitía crear con rapidez pequeños programas, compilarlos y comprobar su funcionamiento. El editor de las versiones 1.x tenía refinamientos como realzar la sintaxis en colores, emparejar llaves y paréntesis, permitir completar el código...
Para mí era el rey para los pequeños programas, mucho más cómodo de utilizar que entornos más pesados, más orientados a proyectos de gran tamaño, como KDevelop. Pero el tiempo ha pasado, y Anjuta ha evolucionado. En las versiones 2.x es "casi imprescindible" crear un proyecto para cualquier cosa. Y si abrimos un único fuente (como el clásico "Hola Mundo"), podremos editarlo, pero no aparecerá en el menú la opción de Compilar. Además, el número de dependencias de otros paquetes ha aumentado, lo que hace que a más de una persona le haya costado incluso ponerlo en funcionamiento...
Por eso, para mí, ha llegado el momento de decir "El rey ha muerto! Viva el (nuevo) rey!", porque existe alternativa. Otro IDE de pequeño tamaño podría ocupar el (maravilloso) lugar de Anjuta 1.2. Se trata de Geany, con características muy similares, aunque todavía se encuentra en fase beta.
¿Geany es la solución para editar y compilar fuentes individuales desde Linux? Todavía no completamente. Aún tiene algún fallo y alguna carencia de relativa importancia. Por ejemplo, en la versión 0.8, la traducción al castellano tiene más de una errata (aun así, será más cómoda que trabajar en inglés para quien no maneje este idioma con soltura); cuando ejecutamos una aplicación en algunas distribuciones de Linux (pocas, afortunadamente *), la ventana de terminal se cierra inmediatamente, sin dar tiempo a leer lo que ha aparecido, y eso no es práctico para probar programas no interactivos; además, en mi caso, tras pulsar el botón "Guardar todo" la aplicación se ha cerrado misteriosamente, y luego no quería volver a arrancar, hasta que no he borrado su carpeta de configuración (".geany")... decididamente hay cosas por corregir.
Pero todavía es un programa en fase inicial. De hecho, insisto en que yo he probado la versión 0.8 y ya está disponible para descarga la 0.9. Quizá incluso esas "pequeñeces" ya estén corregidas. Y si no, la versión 0.10 se espera para Navidad de este año 2006.
Esperemos que este proyecto nos haga la vida más cómoda a los que con frecuencia trabajamos con pequeños fuentes bajo Linux. De momento, las expectativas no son malas...
¿Más detalles? http://geany.uvena.de
(*) Yo he tenido este problema con Ubuntu 6.10, pero no en Fedora Core 5. En un comentario posterior a este artículo tienes más detalles sobre cómo solucionarlo si te encuentras este problema.
05 diciembre 2006
PVM desde Ubuntu 6.10
PVM son las siglas de Parallel Virtual Machine. Es una de las herramientas software disponibles para hacer que varios ordenadores "normales" se puedan comportar como un sistema paralelo.
En Internet es relativamente fácil encontrar recopilaciones de instrucciones que enseñan a instalarlo y ponerlo en marcha. El problema es que la mayoría de ellas están en inglés, y alguna que otra está en español pero ya no se corresponde con lo que actualmente podría resultar la opción más cómoda.
¿Cual sería esa "opción más cómoda"? Posiblemente, emplear un gestor de paquetes como Synaptic (o el que incluya nuestra distribución de Linux) para descargar la herramienta con todas sus dependencias e instalarla.
Pero si usamos esa instalación "automática", quizá las instrucciones que encontremos por Internet ya no nos sean tan útiles. Ese ha sido mi caso, y por ello comentaré lo que he tenido que hacer hasta conseguir que PVM funcionara en mi sistema, por si alguien más se encuentra con el mismo problema.
En mi caso, he usado la distribución de Gnu/Linux conocida como Ubuntu 6.10.
Mi primera opción a la hora de plantearme "jugar" con PVM ha sido ver si aparecía en la lista de paquetes accesibles mediante el gestor de paquetes Synaptic. Efectivamente, en la sección "Desarrollo" del repositorio "universe" se encontraba la versión 3.4.5. He marcado para descarga el paquete "pvm", pero también el "pvm-dev", para poder crear programas para mi "ordenador paralelo".
Hasta aquí sin problemas. Desde un terminal, tecleo "pvm" y puedo entrar, empezamos bien. De momento, volvamos a salir con "halt".
Vamos a comprobar que podemos compilar programas sencillos. Busco el "hello.c" y el "hello_other.c" que deberían estar entre los ejemplos de PVM. Primer problema: la mayoría de instrucciones que había encontrado por Internet decían que PVM suele estar instalado en /usr/share/pvm3/ ... pero no es mi caso. Pido ayuda al bendito "whereis": tecleo "whereis pvm" y me cuenta que ha ido a parar a/usr/lib/pvm3/
Ya sabemos donde buscar. Entro a /usr/lib/pvm3/ y resulta que hay muy poca cosa: una carpeta "bin", casi vacía, otra "conf" con dos ficheros llamados LINUX.def y LINUX.m4 (al menos ya sé el nombre de mi arquitectura), y otra carpeta "lib", en la que se encuentran los supuestos ejecutables "pvm", "pvmd", etc (que realmente son enlaces a ficheros existentes en /usr/bin/).
Pero no hay ejemplos. Bueno, no es grave. Los busco en otra distribución "empaquetada" de PVM, y los copio a mi carpeta de trabajo. Por si alguien no los encuentra, esta es una versión "ligeramente traducida" de hello.c:
----------------
static char rcsid[] =
"$Id: hello.c,v 1.2 1997/07/09 13:24:44 pvmsrc Exp $";
/*
* PVM version 3.4: Parallel Virtual Machine System
* University of Tennessee, Knoxville TN.
* Oak Ridge National Laboratory, Oak Ridge TN.
* Emory University, Atlanta GA.
* Authors: J. J. Dongarra, G. E. Fagg, M. Fischer
* G. A. Geist, J. A. Kohl, R. J. Manchek, P. Mucci,
* P. M. Papadopoulos, S. L. Scott, and V. S. Sunderam
* (C) 1997 All Rights Reserved
*
* NOTICE
*
* Permission to use, copy, modify, and distribute this software and
* its documentation for any purpose and without fee is hereby granted
* provided that the above copyright notice appear in all copies and
* that both the copyright notice and this permission notice appear in
* supporting documentation.
*
* Neither the Institutions (Emory University, Oak Ridge National
* Laboratory, and University of Tennessee) nor the Authors make any
* representations about the suitability of this software for any
* purpose. This software is provided ``as is'' without express or
* implied warranty.
*
* PVM version 3 was funded in part by the U.S. Department of Energy,
* the National Science Foundation and the State of Tennessee.
*/
#include <stdio.h>
#include "pvm3.h"
main()
{
int cc, tid;
char buf[100];
printf("Soy la tarea t%x\n", pvm_mytid());
cc = pvm_spawn("hello_other", (char**)0, 0, "", 1, &tid);
if (cc == 1) {
cc = pvm_recv(-1, -1);
pvm_bufinfo(cc, (int*)0, (int*)0, &tid);
pvm_upkstr(buf);
printf(" respuesta de la tarea t%x: %s\n", tid, buf);
} else
printf("No se ha podido lanzar hello_other\n");
pvm_exit();
}
----------------
y esta sería la equivalente versión "ligeramente traducida" de hello_other.c:
----------------
static char rcsid[] =
"$Id: hello_other.c,v 1.2 1997/07/09 13:24:45 pvmsrc Exp $";
/*
* PVM version 3.4: Parallel Virtual Machine System
* University of Tennessee, Knoxville TN.
* Oak Ridge National Laboratory, Oak Ridge TN.
* Emory University, Atlanta GA.
* Authors: J. J. Dongarra, G. E. Fagg, M. Fischer
* G. A. Geist, J. A. Kohl, R. J. Manchek, P. Mucci,
* P. M. Papadopoulos, S. L. Scott, and V. S. Sunderam
* (C) 1997 All Rights Reserved
*
* NOTICE
*
* Permission to use, copy, modify, and distribute this software and
* its documentation for any purpose and without fee is hereby granted
* provided that the above copyright notice appear in all copies and
* that both the copyright notice and this permission notice appear in
* supporting documentation.
*
* Neither the Institutions (Emory University, Oak Ridge National
* Laboratory, and University of Tennessee) nor the Authors make any
* representations about the suitability of this software for any
* purpose. This software is provided ``as is'' without express or
* implied warranty.
*
* PVM version 3 was funded in part by the U.S. Department of Energy,
* the National Science Foundation and the State of Tennessee.
*/
#include "pvm3.h"
#include <stdio.h>
#include <string.h>
main()
{
int ptid;
char buf[100];
ptid = pvm_parent();
strcpy(buf, "hello, world from ");
gethostname(buf + strlen(buf), 64);
pvm_initsend(PvmDataDefault);
pvm_pkstr(buf);
pvm_send(ptid, 1);
pvm_exit();
exit(0);
}
----------------
Para compilar cada uno de ellos podríamos usar "aimk" o simplemente una línea de comandos como ésta:
cc hello.c -o hello -lpvm3
y lo mismo para el otro fuente:
cc hello_other.c -o hello_other -lpvm3
Los dos ejecutables están preparados. Sería mucha casualidad que todo funcionara ya, pero podemos probarlo. Entramos a "pvm" y tecleamos
spawn -> hello
Con esa orden, debería poner en marcha el programa llamado "hello" y mostrar el resultado en la consola. Pero lo habitual será que no funcione. Deberíamos preparar antes un par de variables de entorno, que le digan dónde está pvm, que arquitectura usamos, etc.
En el caso más favorable, puede que sólo haga falta la variable de entorno que indica dónde están los ejecutables. Salimos de pvm ("halt") y tecleamos:
PVM_PATH=/home/nacho/
export PVM_PATH
(obviamente, en vez de /home/nacho sería la carpeta en que realmente estén nuestros ejecutables)
Ya podemos volver a entrar a "pvm" y volver a intentar el "spawn->hello"
Si no funciona así, quizá debamos "dar todos los pasos": Editamos el fichero ".bashrc" de nuestra carpeta home y le añadimos al final
PVM_ROOT=/usr/lib/pvm3
PVM_ARCH="LINUX"
PATH=$PVM_ROOT/bin:$PATH
export PVM_ROOT PVM_ARCH
Hay por ahí quien dice que es interesante añadirlas también en el /etc/.profile, para que esté accesible a todos los usuarios. También hay quien recomienda añadir la línea
PVM_RSH=/usr/bin/ssh
(y exportarla), para que sea "ssh" el encargado de las conexiones a otros equipos, en vez de rsh.
Pero en teoría sólo con lo anterior debería "casi funcionar". ¿Por qué casi? Porque en principio nuestros ficheros ejecutables se buscarán en PVM_ROOT/bin/PVM_ARCH (en mi caso: /usr/lib/pvm3/bin/LINUX/). Esa carpeta puede no existir, así que deberíamos crearla, y posteriormente copiar los ejecutables en ella. ¿Y si nuestros programas usan ficheros o algún otro dato local? La configuración por defecto es que se guarden en nuestra carpeta "home" (para mí: /home/nacho/)
Una vez que están copiados nuestros ejecutables a la carpeta correcta (o reconfigurado el sistema), si tecleamos "spawn -> hello" deberiamos obtener una respuesta parecida a ésta:
-------
spawn -> hello
[1]
1 successful
t40002
pvm> [1:t40003] EOF
[1:t40002] Soy la tarea t40002
[1:t40002] respuesta de la tarea t40003: hello, world from nacho-laptop
[1:t40002] EOF
[1] finished
-------
Prueba superada. Ahora "sólo" queda comenzar a crear nuestros programas.
Una cosa antes de terminar: se supone que la ventaja de usar PVM es tener una "máquina paralela virtual", así que lo suyo es añadir algún otro equipo a nuestra "máquina paralela", de modo que sí se puedan realizar realmente varias cosas a la vez.
La forma de conseguirlo sería "añadiendo" (add) otro ordenador al nuestro desde pvm, con
add equipo2
El único requisito es que ese otro ordenador nos "dé permiso", para lo que debe contener un fichero "/home/nacho/.rhosts", (en la carpeta "home" que corresponda, claro) que es el que le indica qué equipos pueden conectar mediante "rsh", y qué usuarios pueden conectar desde esos equipos, algo como:
equipo1 nacho
equipo4 juan
Podemos comprobar desde dentro de "pvm" cuantos equipos hay conectados con la orden
conf
¿Más información? Algo hay por ahí...
¡¡¡Valor y... a por ello!!!
En Internet es relativamente fácil encontrar recopilaciones de instrucciones que enseñan a instalarlo y ponerlo en marcha. El problema es que la mayoría de ellas están en inglés, y alguna que otra está en español pero ya no se corresponde con lo que actualmente podría resultar la opción más cómoda.
¿Cual sería esa "opción más cómoda"? Posiblemente, emplear un gestor de paquetes como Synaptic (o el que incluya nuestra distribución de Linux) para descargar la herramienta con todas sus dependencias e instalarla.
Pero si usamos esa instalación "automática", quizá las instrucciones que encontremos por Internet ya no nos sean tan útiles. Ese ha sido mi caso, y por ello comentaré lo que he tenido que hacer hasta conseguir que PVM funcionara en mi sistema, por si alguien más se encuentra con el mismo problema.
En mi caso, he usado la distribución de Gnu/Linux conocida como Ubuntu 6.10.
Mi primera opción a la hora de plantearme "jugar" con PVM ha sido ver si aparecía en la lista de paquetes accesibles mediante el gestor de paquetes Synaptic. Efectivamente, en la sección "Desarrollo" del repositorio "universe" se encontraba la versión 3.4.5. He marcado para descarga el paquete "pvm", pero también el "pvm-dev", para poder crear programas para mi "ordenador paralelo".
Hasta aquí sin problemas. Desde un terminal, tecleo "pvm" y puedo entrar, empezamos bien. De momento, volvamos a salir con "halt".
Vamos a comprobar que podemos compilar programas sencillos. Busco el "hello.c" y el "hello_other.c" que deberían estar entre los ejemplos de PVM. Primer problema: la mayoría de instrucciones que había encontrado por Internet decían que PVM suele estar instalado en /usr/share/pvm3/ ... pero no es mi caso. Pido ayuda al bendito "whereis": tecleo "whereis pvm" y me cuenta que ha ido a parar a/usr/lib/pvm3/
Ya sabemos donde buscar. Entro a /usr/lib/pvm3/ y resulta que hay muy poca cosa: una carpeta "bin", casi vacía, otra "conf" con dos ficheros llamados LINUX.def y LINUX.m4 (al menos ya sé el nombre de mi arquitectura), y otra carpeta "lib", en la que se encuentran los supuestos ejecutables "pvm", "pvmd", etc (que realmente son enlaces a ficheros existentes en /usr/bin/).
Pero no hay ejemplos. Bueno, no es grave. Los busco en otra distribución "empaquetada" de PVM, y los copio a mi carpeta de trabajo. Por si alguien no los encuentra, esta es una versión "ligeramente traducida" de hello.c:
----------------
static char rcsid[] =
"$Id: hello.c,v 1.2 1997/07/09 13:24:44 pvmsrc Exp $";
/*
* PVM version 3.4: Parallel Virtual Machine System
* University of Tennessee, Knoxville TN.
* Oak Ridge National Laboratory, Oak Ridge TN.
* Emory University, Atlanta GA.
* Authors: J. J. Dongarra, G. E. Fagg, M. Fischer
* G. A. Geist, J. A. Kohl, R. J. Manchek, P. Mucci,
* P. M. Papadopoulos, S. L. Scott, and V. S. Sunderam
* (C) 1997 All Rights Reserved
*
* NOTICE
*
* Permission to use, copy, modify, and distribute this software and
* its documentation for any purpose and without fee is hereby granted
* provided that the above copyright notice appear in all copies and
* that both the copyright notice and this permission notice appear in
* supporting documentation.
*
* Neither the Institutions (Emory University, Oak Ridge National
* Laboratory, and University of Tennessee) nor the Authors make any
* representations about the suitability of this software for any
* purpose. This software is provided ``as is'' without express or
* implied warranty.
*
* PVM version 3 was funded in part by the U.S. Department of Energy,
* the National Science Foundation and the State of Tennessee.
*/
#include <stdio.h>
#include "pvm3.h"
main()
{
int cc, tid;
char buf[100];
printf("Soy la tarea t%x\n", pvm_mytid());
cc = pvm_spawn("hello_other", (char**)0, 0, "", 1, &tid);
if (cc == 1) {
cc = pvm_recv(-1, -1);
pvm_bufinfo(cc, (int*)0, (int*)0, &tid);
pvm_upkstr(buf);
printf(" respuesta de la tarea t%x: %s\n", tid, buf);
} else
printf("No se ha podido lanzar hello_other\n");
pvm_exit();
}
----------------
y esta sería la equivalente versión "ligeramente traducida" de hello_other.c:
----------------
static char rcsid[] =
"$Id: hello_other.c,v 1.2 1997/07/09 13:24:45 pvmsrc Exp $";
/*
* PVM version 3.4: Parallel Virtual Machine System
* University of Tennessee, Knoxville TN.
* Oak Ridge National Laboratory, Oak Ridge TN.
* Emory University, Atlanta GA.
* Authors: J. J. Dongarra, G. E. Fagg, M. Fischer
* G. A. Geist, J. A. Kohl, R. J. Manchek, P. Mucci,
* P. M. Papadopoulos, S. L. Scott, and V. S. Sunderam
* (C) 1997 All Rights Reserved
*
* NOTICE
*
* Permission to use, copy, modify, and distribute this software and
* its documentation for any purpose and without fee is hereby granted
* provided that the above copyright notice appear in all copies and
* that both the copyright notice and this permission notice appear in
* supporting documentation.
*
* Neither the Institutions (Emory University, Oak Ridge National
* Laboratory, and University of Tennessee) nor the Authors make any
* representations about the suitability of this software for any
* purpose. This software is provided ``as is'' without express or
* implied warranty.
*
* PVM version 3 was funded in part by the U.S. Department of Energy,
* the National Science Foundation and the State of Tennessee.
*/
#include "pvm3.h"
#include <stdio.h>
main()
{
int ptid;
char buf[100];
ptid = pvm_parent();
strcpy(buf, "hello, world from ");
gethostname(buf + strlen(buf), 64);
pvm_initsend(PvmDataDefault);
pvm_pkstr(buf);
pvm_send(ptid, 1);
pvm_exit();
exit(0);
}
----------------
Para compilar cada uno de ellos podríamos usar "aimk" o simplemente una línea de comandos como ésta:
cc hello.c -o hello -lpvm3
y lo mismo para el otro fuente:
cc hello_other.c -o hello_other -lpvm3
Los dos ejecutables están preparados. Sería mucha casualidad que todo funcionara ya, pero podemos probarlo. Entramos a "pvm" y tecleamos
spawn -> hello
Con esa orden, debería poner en marcha el programa llamado "hello" y mostrar el resultado en la consola. Pero lo habitual será que no funcione. Deberíamos preparar antes un par de variables de entorno, que le digan dónde está pvm, que arquitectura usamos, etc.
En el caso más favorable, puede que sólo haga falta la variable de entorno que indica dónde están los ejecutables. Salimos de pvm ("halt") y tecleamos:
PVM_PATH=/home/nacho/
export PVM_PATH
(obviamente, en vez de /home/nacho sería la carpeta en que realmente estén nuestros ejecutables)
Ya podemos volver a entrar a "pvm" y volver a intentar el "spawn->hello"
Si no funciona así, quizá debamos "dar todos los pasos": Editamos el fichero ".bashrc" de nuestra carpeta home y le añadimos al final
PVM_ROOT=/usr/lib/pvm3
PVM_ARCH="LINUX"
PATH=$PVM_ROOT/bin:$PATH
export PVM_ROOT PVM_ARCH
Hay por ahí quien dice que es interesante añadirlas también en el /etc/.profile, para que esté accesible a todos los usuarios. También hay quien recomienda añadir la línea
PVM_RSH=/usr/bin/ssh
(y exportarla), para que sea "ssh" el encargado de las conexiones a otros equipos, en vez de rsh.
Pero en teoría sólo con lo anterior debería "casi funcionar". ¿Por qué casi? Porque en principio nuestros ficheros ejecutables se buscarán en PVM_ROOT/bin/PVM_ARCH (en mi caso: /usr/lib/pvm3/bin/LINUX/). Esa carpeta puede no existir, así que deberíamos crearla, y posteriormente copiar los ejecutables en ella. ¿Y si nuestros programas usan ficheros o algún otro dato local? La configuración por defecto es que se guarden en nuestra carpeta "home" (para mí: /home/nacho/)
Una vez que están copiados nuestros ejecutables a la carpeta correcta (o reconfigurado el sistema), si tecleamos "spawn -> hello" deberiamos obtener una respuesta parecida a ésta:
-------
spawn -> hello
[1]
1 successful
t40002
pvm> [1:t40003] EOF
[1:t40002] Soy la tarea t40002
[1:t40002] respuesta de la tarea t40003: hello, world from nacho-laptop
[1:t40002] EOF
[1] finished
-------
Prueba superada. Ahora "sólo" queda comenzar a crear nuestros programas.
Una cosa antes de terminar: se supone que la ventaja de usar PVM es tener una "máquina paralela virtual", así que lo suyo es añadir algún otro equipo a nuestra "máquina paralela", de modo que sí se puedan realizar realmente varias cosas a la vez.
La forma de conseguirlo sería "añadiendo" (add) otro ordenador al nuestro desde pvm, con
add equipo2
El único requisito es que ese otro ordenador nos "dé permiso", para lo que debe contener un fichero "/home/nacho/.rhosts", (en la carpeta "home" que corresponda, claro) que es el que le indica qué equipos pueden conectar mediante "rsh", y qué usuarios pueden conectar desde esos equipos, algo como:
equipo1 nacho
equipo4 juan
Podemos comprobar desde dentro de "pvm" cuantos equipos hay conectados con la orden
conf
¿Más información? Algo hay por ahí...
- Para las órdenes durante el manejo de PVM, como "spawn", se puede pedir ayuda al de siempre: "man pvm"
- Para variables de entorno, como PVM_ROOT y sus valores por defecto, "man pvm_intro" debería resumirlas todas.
- Para aprender a usar las funciones de comunicación incluidas en PVM, como pvm_spawn y pvm_recv, habrá que buscar algún tutorial. Hay pocos, y casi todos en inglés... pero esa es otra historia, y deberá ser contada en otro momento... ;-)
¡¡¡Valor y... a por ello!!!
29 noviembre 2006
DJGPP sigue vivo
DJGPP es una adaptación al sistema operativo MsDos del compilador de C de GNU, realizada por DJ Delorie a partir de 1989.
La primera versión se basaba en el compilador "gcc" versión 1.35, y la más reciente (a fecha noviembre de 2006), casi 20 años después, se apoya en la 4.10.
Está originalmente diseñado para MsDos, pero las versiones recientes del entorno funcionan muy bien bajo Windows, permiten nombres de ficheros largos (incluso con espacios, aunque no es recomendable para los fuentes) y manejo de ratón... en modo texto.
La apariencia del entorno, que recuerda mucho a los compiladores de Borland, es ésta:

Sigue siendo un compilador ideal para quien no tiene un ordenador muy potente, o quien necesita aprender programación en un centro de enseñanza que utiliza la platforma Linux y busca una alternativa que le permita practicar en casa sin necesidad de instalar un Linux en su equipo.
Su web oficial es www.delorie.com/djgpp/, pero en ella toda la información que encontrarás está en inglés. Si no te aclaras con el inglés y quieres saltar directamente a la página de descargas, la tienes en www.delorie.com/djgpp/zip-picker.html. En ella puedes elegir qué compiladores quieres (sólo C, o bien incluir otros lenguajes como C++, que es razonable hoy en día, o como Objective C, menos usado). También puedes incluir en la descarga algunos extras recomendables, como el entorno integrado RHIDE (el que aparece en la imagen anterior), o la librería "curses" para acceder a la pantalla siguiendo el estándar de Unix (Linux), o incluso la biblioteca gráfica Allegro, muy usada para crear juegos y programas que tengan que mostrar gráficos en pantalla. Los más atrevidos pueden incluso descargar el código fuente de todas las herramientas.
Eso sí, todo esto nos puede suponer descargar cerca de 30 ficheros ZIP, que habría que descomprimir a mano en sus carpetas correctas, y posteriormente se debería crear una variable de entorno y actualizar el PATH del sistema. Todo ello está explicado (en inglés) en la página oficial, y no debería suponer ningún problema para quien ya ha manejado MsDos o el intérprete de comandos de Linux. Pero si este no es tu caso, todavía no está todo perdido...
Si te apetece probarlo desde Windows, pero no te atreves con la instalación "normal", aquí tienes una opción alternativa: puedes descargar este fichero djgpp_instalado.zip (de unos 23 Mb de tamaño), descomprimirlo en la carpeta raíz de tu disco C (debería bastar con hacer doble clic en el fichero para ver su contenido, elegir "copiar" la carpeta llamada "djgpp", desplazarte al disco C y elegir "pegar"), entrar a la nueva carpeta "djgpp" y hacer doble clic en "start". Si lo vas a usar con una cierta frecuencia, te será más cómodo tener un acceso directo en el escritorio (botón derecho sobre el fichero Start, escoger la opción "Enviar a" y la subopción "Escritorio, crear acceso directo".
Este fichero "start" se encarga de crear momentáneamente la variable de entorno, actualizar el PATH y poner en marcha el entorno RHIDE, para que no tengas preocuparte de la parte incómoda.
¡Suerte!
La primera versión se basaba en el compilador "gcc" versión 1.35, y la más reciente (a fecha noviembre de 2006), casi 20 años después, se apoya en la 4.10.
Está originalmente diseñado para MsDos, pero las versiones recientes del entorno funcionan muy bien bajo Windows, permiten nombres de ficheros largos (incluso con espacios, aunque no es recomendable para los fuentes) y manejo de ratón... en modo texto.
La apariencia del entorno, que recuerda mucho a los compiladores de Borland, es ésta:
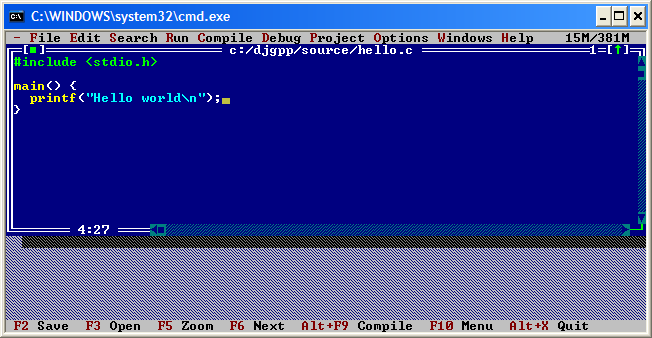
Sigue siendo un compilador ideal para quien no tiene un ordenador muy potente, o quien necesita aprender programación en un centro de enseñanza que utiliza la platforma Linux y busca una alternativa que le permita practicar en casa sin necesidad de instalar un Linux en su equipo.
Su web oficial es www.delorie.com/djgpp/, pero en ella toda la información que encontrarás está en inglés. Si no te aclaras con el inglés y quieres saltar directamente a la página de descargas, la tienes en www.delorie.com/djgpp/zip-picker.html. En ella puedes elegir qué compiladores quieres (sólo C, o bien incluir otros lenguajes como C++, que es razonable hoy en día, o como Objective C, menos usado). También puedes incluir en la descarga algunos extras recomendables, como el entorno integrado RHIDE (el que aparece en la imagen anterior), o la librería "curses" para acceder a la pantalla siguiendo el estándar de Unix (Linux), o incluso la biblioteca gráfica Allegro, muy usada para crear juegos y programas que tengan que mostrar gráficos en pantalla. Los más atrevidos pueden incluso descargar el código fuente de todas las herramientas.
Eso sí, todo esto nos puede suponer descargar cerca de 30 ficheros ZIP, que habría que descomprimir a mano en sus carpetas correctas, y posteriormente se debería crear una variable de entorno y actualizar el PATH del sistema. Todo ello está explicado (en inglés) en la página oficial, y no debería suponer ningún problema para quien ya ha manejado MsDos o el intérprete de comandos de Linux. Pero si este no es tu caso, todavía no está todo perdido...
Si te apetece probarlo desde Windows, pero no te atreves con la instalación "normal", aquí tienes una opción alternativa: puedes descargar este fichero djgpp_instalado.zip (de unos 23 Mb de tamaño), descomprimirlo en la carpeta raíz de tu disco C (debería bastar con hacer doble clic en el fichero para ver su contenido, elegir "copiar" la carpeta llamada "djgpp", desplazarte al disco C y elegir "pegar"), entrar a la nueva carpeta "djgpp" y hacer doble clic en "start". Si lo vas a usar con una cierta frecuencia, te será más cómodo tener un acceso directo en el escritorio (botón derecho sobre el fichero Start, escoger la opción "Enviar a" y la subopción "Escritorio, crear acceso directo".
Este fichero "start" se encarga de crear momentáneamente la variable de entorno, actualizar el PATH y poner en marcha el entorno RHIDE, para que no tengas preocuparte de la parte incómoda.
¡Suerte!
¿Para qué?
¿Qué voy a hacer desde aquí?
Poca cosa ;-) Básicamente, comentar novedades que lleguen a mis oídos y que estén relacionadas con el mundo de la programación de ordenadores.
Generalmente se tratará de reseñas cortas, introductorias, con algún enlace a la página oficial correspondiente y a artículos más detallados para quien quiera ampliar la información.
El nivel buscado generalmente será el de un principiante en la programación. Aun así, intentaré guiar a artículos más detallados a quien desee (o necesite) profundizar más.
Espero que la idea te parezca interesante...
Poca cosa ;-) Básicamente, comentar novedades que lleguen a mis oídos y que estén relacionadas con el mundo de la programación de ordenadores.
Generalmente se tratará de reseñas cortas, introductorias, con algún enlace a la página oficial correspondiente y a artículos más detallados para quien quiera ampliar la información.
El nivel buscado generalmente será el de un principiante en la programación. Aun así, intentaré guiar a artículos más detallados a quien desee (o necesite) profundizar más.
Espero que la idea te parezca interesante...
Suscribirse a:
Entradas (Atom)

